OpenAI’s API tokens are fundamental to interacting with models such as GPT-4, GPT-4o, and GPT-3.5. Understanding how tokens work helps developers optimize costs, improve model efficiency, and ensure better response quality. This article will break down how OpenAI API tokens function, how they are counted, their cost implications, and best practices for managing token usage.

1. What Are OpenAI API Tokens?
Tokens are the fundamental unit of processing for OpenAI models. They represent chunks of words or characters that the model reads and generates. OpenAI’s API processes both input tokens (the text you send) and output tokens (the response generated by the model).
For reference:
- The word "Hello" is one token.
- The sentence "How are you today?" is roughly 5 tokens.
- A typical paragraph of text is around 100 tokens.
Tokenization Breakdown
OpenAI uses Byte Pair Encoding (BPE) to split text into tokens. Some words are a single token, while others are broken down into multiple tokens, particularly rare or long words.
Examples:
- "Artificial Intelligence" → 2 tokens
- "Uncharacteristically" → 4 tokens
- "Hello! How's your day going?" → 7 tokens
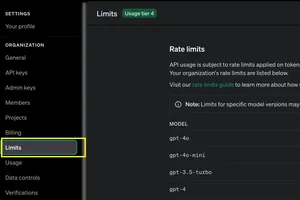
2. Token Limits and Context Windows
Each OpenAI model has a maximum context window, meaning it can process only a certain number of tokens at once (both input and output). Here are the token limits for different models:
| Model | Max Tokens (Context Length) |
|---|---|
| GPT-4o | 128,000 tokens |
| GPT-4 | 32,000 tokens |
| GPT-3.5-turbo | 16,000 tokens |
The context window includes both the input prompt and the generated response. If the total tokens exceed the model’s limit, older tokens are truncated, potentially impacting response quality.
3. How OpenAI API Charges for Tokens
OpenAI charges based on the number of tokens used in a request. This includes both input and output tokens. Here is a basic pricing breakdown:
| Model | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) |
| GPT-4o | $2.5 | $10 |
| GPT-4 | $30.00 | $60.00 |
| GPT-3.5-turbo | $8 | $6 |
Note: Prices are subject to change based on OpenAI’s pricing policies. Always refer to the official pricing page for the latest updates.
Cost Optimization Tips
- Use GPT-3.5-turbo for simple tasks to reduce costs.
- Keep prompts concise to minimize input tokens.
- Limit response length to control output tokens.
- Utilize function calling to structure API responses efficiently.
4. How to Calculate Tokens
To determine how many tokens your text will use before making an API call, OpenAI provides a tokenizer tool.
import openai
import tiktoken
def count_tokens(text, model="gpt-4"):
enc = tiktoken.encoding_for_model(model)
return len(enc.encode(text))
text = "Understanding OpenAI API tokens is crucial for developers."
print("Token count:", count_tokens(text))This script helps you estimate token usage, which is essential for budgeting and optimization.
5. Managing Token Usage Efficiently
Best Practices:
- Summarize Input Data: Avoid sending large documents; summarize key points.
- Use System Messages Wisely: System messages guide the model but contribute to token count. Keep them concise.
- Set Token Limits: Use the
max_tokensparameter to control response length. - Monitor Token Consumption: Use OpenAI’s API usage dashboard to track token spending.
Example API Call with Token Limit
import openai
import os
async def generate_response(prompt):
client = openai.AsyncOpenAI(api_key=os.getenv("OPENAI_API_KEY"))
response = await client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
max_tokens=200
)
return response.choices[0].message.content
prompt = "Explain the importance of tokenization in NLP."
print(asyncio.run(generate_response(prompt)))This ensures that responses remain within a manageable token range.
6. Conclusion
Understanding OpenAI API tokens is crucial for optimizing costs and ensuring efficient API usage. By knowing how tokens are counted, charged, and managed, developers can build cost-effective and high-performing applications. Whether you're using GPT-4o for advanced AI tasks or GPT-3.5-turbo for lightweight operations, managing tokens effectively will lead to better AI-driven experiences.